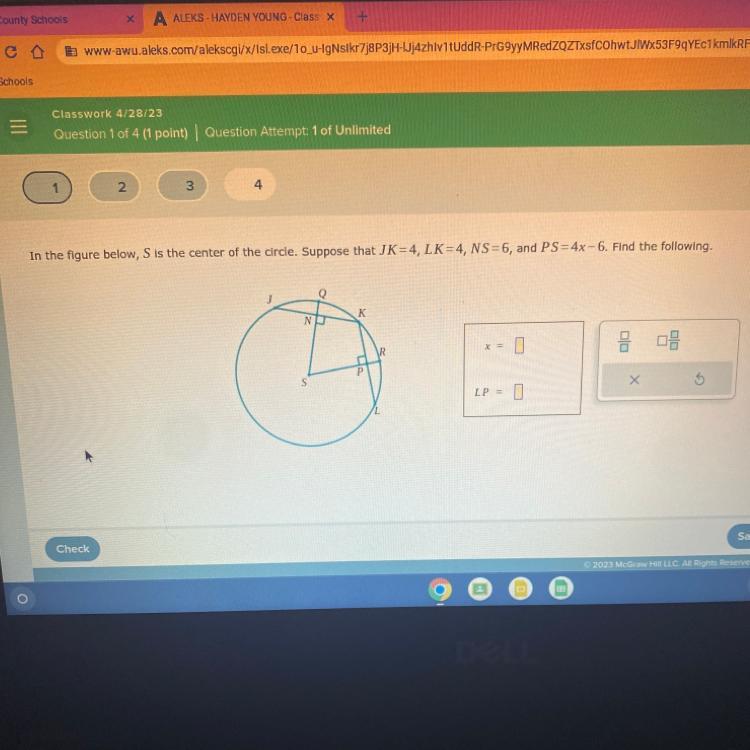
Answers
Answer:
x= 3
and LP is probably 2
NOTE: I'm not to exactly sure for answer LP but I am sure that X = 3
Related Questions
This exercise explores the effect of linear transformations f :R² + R2. (a) For points v, w E R², let l be the line segment joining them (i.e., I consists of the convex linear combinations tv + (1 – t)w with 0 0, so the third is at (a,b) with b + 0 (as the third vertex cannot be on the line through the other two vertices); any triangle can be arranged to be such a T by sliding and rotating it in RP
Answers
This exercise explores the effect of linear transformations on points in R² to R². It considers the line segment between two points and the concept of a "triangle inequality" for any three points on a plane.
The exercise focuses on the effect of linear transformations on points in R² (a 2-dimensional space) to R². It starts by considering two points, v and w, in R² and defines the line segment l that joins them. This line segment is characterized by the convex linear combinations of v and w, where t ranges from 0 to 1. These combinations represent the points along the line segment.
The exercise then introduces the concept of a "triangle inequality" for any three points on a plane. It states that for any three points, v, w, and u, on a plane, the distance between v and u is less than or equal to the sum of the distances between v and w, and between w and u. This inequality helps establish the relationship between the points in the triangle formed by v, w, and u.
To further explore this concept, the exercise introduces a triangle T with vertices v, w, and u. It states that the first two vertices, v and w, are at (0,0) and (1,0) respectively. The third vertex, u, is at (a,b) with b > 0. This condition ensures that the third vertex cannot lie on the line passing through the other two vertices. The exercise suggests that any triangle can be transformed to such a T by sliding and rotating it in RP, the real projective plane.
Overall, the exercise delves into the impact of linear transformations on points in R² and emphasizes the triangle inequality as a fundamental concept for analyzing the relationships between points on a plane.
Learn more about triangle inequality here:
https://brainly.com/question/30095626
#SPJ11
Which statement is true for any matrix A? I. If rank(A) is equal to the number of columns of A, then the linear system Ax=b has a solution for all b. II. If rank(A) is equal to the number of rows of A, then the linear system Ax = 0 has a unique solution. Both I and II. Neither I nor II. Only II. Only I.
Answers
only statement II is true for any matrix A, while statement I is false.
Statement I states that if the rank of matrix A is equal to the number of columns of A, then the linear system Ax=b has a solution for all b. This statement is not always true. The condition for the linear system Ax=b to have a solution for all b is that the rank of A is equal to the number of rows of A, not the number of columns. Therefore, statement I is false.
Statement II states that if the rank of matrix A is equal to the number of rows of A, then the linear system Ax=0 has a unique solution. This statement is true for any matrix A. When the rank of A is equal to the number of rows, it implies that there are no redundant or dependent rows in A, leading to a unique solution for the homogeneous system Ax=0. Therefore, statement II is true.
learn more about matrix here:
https://brainly.com/question/29132693
#SPJ11
If the angle of incidence is 35 ∘ , what is the angle of refraction? (consider that light can travel to the interface from either material.) enter your answers in ascending order separated by a comma.
Answers
The angle of refraction is approximately 23.68°.
To solve this problem, we need to use Snell's law, which relates the angles of incidence and refraction to the refractive indices of the materials. The formula is:
n1 sin θ1 = n2 sin θ2
where n1 and n2 are the refractive indices of the materials, θ1 is the angle of incidence, and θ2 is the angle of refraction.
Since we are not given the materials, we cannot find the refractive indices. However, we can still find the angle of refraction in terms of the angle of incidence by using the fact that the angles are related by:
[tex]θ2 = sin^-1((n1/n2)sinθ1)[/tex]
We can use this formula to find the angle of refraction in terms of the angle of incidence:
[tex]θ2 = sin^-1((1/1.5)sin35°) ≈ 23.68°[/tex]
Therefore, the angle of refraction is approximately 23.68°.
To know more about refraction refer to-
https://brainly.com/question/14760207
#SPJ11
Find the sum of the following series. round to the nearest hundredth if necessary.
9 + 18 + 36 + ... + 576
Answers
To find the sum of the given series: 9 + 18 + 36 + ... + 576,
we first need to recognize the pattern of the series, as this series has a common ratio of 2,making it a geometric sequence.
The first term, a1 = 9, and the common ratio r = 2.
Now, we can use the formula for the sum of the first n terms of a geometric sequence:
Sn = a(1 - r^n) / (1 - r),
where n is the number of terms, a is the first term, and r is the common ratio.
We don't know the value of n yet, so we need to find it.
To find n, we need to find the value of the last term in the series that is less than or equal to 576.
We know that the nth term of a geometric sequence can be calculated as:
an = a1 * r^(n-1)
So we can write:
[tex]576 = 9 * 2^(n-1)2^(n-1) = 576/9n - 1 = log2(576/9)n - 1 = 5.14 (rounded to 2 decimal places)n = 6.14 (rounded up to the nearest whole number)n = 7[/tex]
Now we have all the values needed to find the sum of the series:
[tex]S7 = 9 + 18 + 36 + ... + 576 = a(1 - r^n) / (1 - r)= 9(1 - 2^7) / (1 - 2) = 9(1 - 128) / (-1) = 1113[/tex]
So the sum of the series is 1113. Answer: 1113
To know more about geometric sequence, visit:
https://brainly.com/question/27852674
#SPJ11
the highest common factor of 2,3 and 7 is
Answers
Answer:42
Step-by-step explanation:
LCM OF 2 , 3 & 7 is 42
Answer:
Step-by-step explanation:
Consider the following two successive reactionsC-->MM-->Х If the percent yield of the first reaction is 66.9% and the percent yield of the second reaction is 31,6%, what is the overall percent yield for C-->X?a. 10.9% b. 17.3% c. 11.3% d. 21.1% e.16.8%
Answers
The overall percent yield for C --> X is approximately 21.1% (answer choice d).
A chemical reaction's efficiency is gauged by its percent yield. It is the theoretical yield—the greatest quantity of product that could be obtained if the reaction proceeded to completion—to the actual yield, the amount of product that was received from the reaction, represented as a percentage. Reaction conditions, contaminants, and incomplete reactions are only a few of the variables that can have an impact on the percent yield.
To find the overall percent yield for the successive reactions C --> M and M --> X, you need to multiply the percent yields of each reaction together and then divide by 100.
First, let's identify the percent yield for each reaction:
Reaction 1 (C --> M): 66.9%
Reaction 2 (M --> X): 31.6%
Now, multiply the percent yields together:
(66.9/100) * (31.6/100)
Then, multiply the result by 100 to convert back to a percentage:
(0.669 * 0.316) * 100
Calculate the result:
21.13364
The overall percent yield for C --> X is approximately 21.1% (answer choice d).
Learn more about percent yield here:
https://brainly.com/question/31603690
#SPJ11
The number of flu cases in a certain town rose from approximately 100 in one week to 180 in the next. Assume the number of cases is growing exponentially. a. Use this information to build an exponential model for the number of flu cases N(t), as a function of the time t in weeks. Assume t = 0 is the week with 100 cases. Round A and b to 3 significant figures if necessary. b. Use your model to find N(5). c. Interpret your answer for part b.
Answers
a. Constructing the exponential model:
The equation [tex]N(t) = A times Bt[/tex] can be used to depict an exponential functin.
N(t) is the number of flu cases at time t,
A is the number of cases at the beginning, and B is the current number of cases.
b. The exponential model for the number of flu cases is[tex]N(t) = 100 \times 1.8^t.[/tex]
c. Interpretation of part b results:
The exponential model predicts that at t = 5 weeks, there will be roughly 1863 flu cases in the town.
This demonstrates the flu's explosive proliferation during a five-week timeframe.
a. Building the exponential model:
An exponential function can be represented by the equation [tex]N(t) = A \times B^t,[/tex]
where N(t) is the number of flu cases at time t,
A is the initial number of cases,
B is the growth factor, and t is the time in weeks.
We know that N(0) = 100 and N(1) = 180.
First, we need to find the growth factor,
B. Using the data given:
[tex]100 \times B^0 = 100[/tex] (since t=0 is the week with 100 cases)
[tex]100 \times B^1 = 180[/tex] (since t=1 is the week with 180 cases)
From the first equation, we have A = 100.
From the second equation:
100 * B = 180
B = 180/100
B = 1.8
So, the exponential model for the number of flu cases is[tex]N(t) = 100 \times 1.8^t.[/tex]
b. Finding N(5):
Now we need to find the number of flu cases at t = 5 weeks using the model:
[tex]N(5) = 100 \times 1.8^5[/tex].
N(5) ≈ 1863.3
c. Interpretation of the result for part b:
At t = 5 weeks, there will be approximately 1863 flu cases in the town, according to the exponential model.
This shows the rapid growth of flu cases over a period of 5 weeks.
For similar question on exponential model.
https://brainly.com/question/2456547
#SPJ11
Find the rectangular coordinates of the point whose polar coordinates are (−5,).If appropriate, leave all radicals in your answer.
Answers
The x-coordinate is x = 5 * cos(θ), and the y-coordinate is y = 5 * sin(θ).
The point with polar coordinates (-5, θ) can be represented in rectangular coordinates. To find the rectangular coordinates, we need to convert the polar coordinates to rectangular form using trigonometric functions.
To find the rectangular coordinates of a point given its polar coordinates (-5, θ), we can use the following formulas: x = r * cos(θ) and y = r * sin(θ), where r represents the distance from the origin to the point, and θ represents the angle measured counter-clockwise from the positive x-axis.
In this case, the given polar coordinate is (-5, θ), where the distance from the origin to the point is 5 units (r = 5). To find the rectangular coordinates, we substitute the values of r and θ into the formulas. The x-coordinate is x = 5 * cos(θ), and the y-coordinate is y = 5 * sin(θ).
The resulting rectangular coordinates depend on the specific value of θ. By substituting the given angle into the formulas, we can evaluate the cosine and sine functions to find the corresponding x and y coordinates. It's important to note that if the angle involves trigonometric functions with radicals, the final rectangular coordinates should be left in radical form.
Learn more about polar coordinates here:
https://brainly.com/question/31904915
#SPJ11
A list has 80 numbers, of which the largest is 768. Suppose that the 768 is replaced by 868. Does the median of the list change? If yes, how much? If no, why not? Does the mean change? If yes, how much? If no, why not? ·Does the 10% trimmed mean change? If yes, how much? If no, why not?
Answers
Median may change by 100, mean changes by at most 100, 10% trimmed mean does not change.
How does replacing the largest number affect the median, mean, and 10% trimmed mean?Replacing the largest number in a list of 80 numbers from 768 to 868 will result in a change in the median and the mean, but not in the 10% trimmed mean.
The median will increase by 100 since it is the middle number when the list is sorted, and replacing the largest number will shift the original largest number down by one position.
The mean may change by at most 100, as the change in the largest number is divided among all the numbers in the list, so the effect on the mean depends on the distribution of the numbers in the list. The 10% trimmed mean does not change since it removes the top and bottom 10% of the data, regardless of the values in those positions.
Learn more about list
brainly.com/question/31308313
#SPJ11
Using appropriate properties find 4/7*-3/5+1/6*3/2-3/14*4/7
Answers
The simplified value of the expression is -1/35.
To simplify the expression 4/7 * -3/5 + 1/6 * 3/2 - 3/14 * 4/7, we can apply the properties of multiplication and addition/subtraction of fractions.
First, let's simplify each term separately:
4/7 * -3/5 = (-12/35)
1/6 * 3/2 = (3/12) = (1/4)
3/14 * 4/7 = (12/98) = (6/49)
Now, let's combine the simplified terms:
(-12/35) + (1/4) - (6/49)
To add or subtract fractions, we need a common denominator. In this case, the least common denominator (LCD) of 35, 4, and 49 is 140.
Converting each fraction to have a denominator of 140:
(-12/35) * (4/4) = (-48/140)
(1/4) * (35/35) = (35/140)
(6/49) * (4/4) = (24/196)
Now, we can combine the fractions:
(-48/140) + (35/140) - (24/196)
To add or subtract fractions, we need the denominators to be the same. The LCD of 140 and 196 is 27440.
Converting each fraction to have a denominator of 27440:
(-48/140) * (196/196) = (-9408/27440)
(35/140) * (196/196) = (6860/27440)
(24/196) * (140/140) = (3360/27440)
Now, we can combine the fractions:
(-9408/27440) + (6860/27440) - (3360/27440) = -5908/27440 = -1/35
Therefore, the final simplified value of the expression 4/7 * -3/5 + 1/6 * 3/2 - 3/14 * 4/7 is -1/35.
Visit here to learn more about fractions:
brainly.com/question/1301963
#SPJ11
Use the given information to find the P-value. Also, use a 0.05 significance level and state the conclusion about the null hypothesis (reject the null hypothesis or fail to reject the null hypothesis).
With H1: p ? 4/5, the test statistic is z = 1.52.
Answers
The conclusion about the null hypothesis is that we fail to reject it. We cannot conclude that the proportion is greater than 4/5 based on the available data and the chosen level of significance.
To find the P-value, we need to look up the probability of getting a test statistic as extreme or more extreme than the observed value of 1.52 under the null hypothesis.
Since the alternative hypothesis is one-sided (p > 4/5), we will use the upper tail of the standard normal distribution.
Using a standard normal table or a calculator, we can find that the probability of getting a z-score of 1.52 or higher is approximately 0.0643. This is the P-value.
Now we compare the P-value to the significance level of 0.05. Since the P-value is greater than the significance level, we fail to reject the null hypothesis.
In other words, we do not have enough evidence to conclude that the true population proportion is greater than 4/5 at the 0.05 level of significance.
Therefore, the conclusion about the null hypothesis is that we fail to reject it. We cannot conclude that the proportion is greater than 4/5 based on the available data and the chosen level of significance.
Know more about null hypothesis here:
https://brainly.com/question/4436370
#SPJ11
Find the vector PO X PR if P = (2,1,0), Q = (1,5,2), R = (-1,13,6) (Give your answer using component form or standard basis vectors. Express numbers in exact form. Use symbolic notation and fractions where needed.)
Answers
The vector PO x PR is simply: PO x PR = 15 n = (15, 0, 0) Expressed in component form or standard basis vectors, the vector is (15, 0, 0).
First, we need to find the vectors PO and PR:
PO = O - P = (-2, -1, 0)
PR = R - P = (-3, 12, 6)
To find the cross product of PO and PR, we can use the following formula:
PO x PR = |PO| |PR| sinθ n
where |PO| and |PR| are the magnitudes of the vectors PO and PR, θ is the angle between them, and n is a unit vector perpendicular to both PO and PR. Since θ = 90 degrees and |PO| = sqrt(5) and |PR| = 15, we have:
PO x PR = (sqrt(5) * 15) n = 15 sqrt(5) n
To find n, we can take the unit vector in the direction of PO x PR:
n = (1 / |PO x PR|) (PO x PR) = (1 / (15 sqrt(5))) (15 sqrt(5) n) = n
Therefore, the vector PO x PR is simply:
PO x PR = 15 n = (15, 0, 0)
Expressed in component form or standard basis vectors, the vector is (15, 0, 0).
To know more about vector refer to-
https://brainly.com/question/29740341
#SPJ11
Barba bought 5 amusement park tickets at a cost of $30. If she bought 7 tickets how much would it cost
Answers
In this given scenario, if Barba were to buy 7 tickets, she would need to pay $42 in total.
Barba purchased 5 amusement park tickets for a total cost of $30.
To determine the cost of 7 tickets, we first need to find the cost of one ticket, which we assume to be x.
By dividing the total cost of $30 by the number of tickets (5), we find that each ticket is priced at $6.
Substituting this value into the equation, we can calculate the cost of 7 tickets by multiplying the cost of one ticket ($6) by the number of tickets (7), resulting in a total cost of $42.
Therefore, if Barba were to buy 7 tickets, she would need to pay $42 in total.
To know more about total cost, visit:
https://brainly.com/question/30355738
#SPJ11
Given that λ1=3 is one the eigenvalues of the matrix
A=[ 1 1 3
1 5 1
3 1 1
]
calculate the other two eigenvalues λ2, λ3 and the eigenvectors corresponding to each of the eigenvalues.
Answers
The other two eigenvalues of the matrix A are λ2 and λ3, and their corresponding eigenvectors can be calculated.
What are the other eigenvalues?To find the eigenvalues and eigenvectors, we start by solving the characteristic equation det(A - λI) = 0, where A is the given matrix, λ represents the eigenvalue, and I is the identity matrix.
For the matrix A = [1 1 3; 1 5 1; 3 1 1], we subtract λ times the identity matrix from A and calculate the determinant. Setting the determinant equal to zero, we can solve for the eigenvalues.
Once we solve the characteristic equation, we find that one of the eigenvalues is given as λ1 = 3. To find the other two eigenvalues, we can either solve the equation algebraically or use numerical methods.
Once we have the eigenvalues, we can find their corresponding eigenvectors by solving the equation (A - λI)X = 0, where X is the eigenvector associated with the eigenvalue λ.
Learn more about eigenvalues
brainly.com/question/29861415
#SPJ11
Help please on picture
Answers
The factorization of the expressions are
1. a. 9y-12 = 3 ( 3y -4)
b. 6-4x = 2( 3-2x)
c. 25y-35z = 5( 5y -7z)
d. 42y+28x-56c = 14( 3y+ 2x -4c)
2. a. x²-3x = x( x-3)
b. 4w²+10w = 2w( 2w+5)
c. x³+2x² = x²( x+2)
d. xy+xz = x( y+z)
What is factorization?Factoring or factorization an expression can be defined as writing an algebraic expression as a product of its factors.
For example 6x +2 can be factored by finding the expression highest common factor which is 2 and bring it out from each term
therefore ;
6x+2 = 2( 3x+1) .
Also 9y -12 , the highest common factor = 3
= 3( 3y -4)
learn more about factorization from
https://brainly.com/question/25829061
#SPJ1
1. Use the method of Example 3 to show that the following set of vectors forms a basis for R2. {(2, 1), (3,0) 2. In each part, determine whether the vectors are linearly inde- pendent or are linearly dependent in R?. (a) (-3,0, 4), (5, -1, 2), (1, 1, 3) (b) (-2,0,1), (3, 2, 5), (6,-1, 1), (7,0, -2)
Answers
The set of vectors {(2, 1), (3, 0)} forms a basis for R2, and (a) the vectors are linearly independent in R3, and (b) the vectors are linearly dependent in R3.
To show that the set of vectors {(2, 1), (3, 0)} forms a basis for R2, we need to show that the vectors are linearly independent and span R2.
Linear independence: Assume that there exist scalars a and b such that a(2, 1) + b(3, 0) = (0, 0). This gives us the system of equations:
2a + 3b = 0
a = 0
Solving this system, we get a = b = 0. Therefore, the vectors are linearly independent.
Span: Let (x, y) be an arbitrary vector in R2. We need to show that there exist scalars a and b such that a(2, 1) + b(3, 0) = (x, y). Solving this system of equations gives us:
a = (3y - bx)/(6 - b)
b can be any non-zero real number since it cannot be 0 (otherwise, the vectors would be linearly dependent). Therefore, we can choose b = 1. This gives us:
a = (3y - x)/3
Therefore, any vector (x, y) in R2 can be written as a linear combination of the given vectors. Hence, the set of vectors {(2, 1), (3, 0)} forms a basis for R2.
(a) To check if the vectors (-3, 0, 4), (5, -1, 2), and (1, 1, 3) are linearly independent or not, we can write them as the columns of a matrix and perform row operations to see if we can reduce the matrix to row echelon form with all leading coefficients being 1.
[ -3 5 1 ]
[ 0 -1 1 ]
[ 4 2 3 ]
Performing row operations, we get:
[ 1 0 1/2 ]
[ 0 1 -1/2 ]
[ 0 0 0 ]
Since we have a row of zeros, the matrix cannot be reduced to row echelon form with all leading coefficients being 1. Therefore, the vectors are linearly dependent.
(b) To check if the vectors (-2, 0, 1), (3, 2, 5), (6, -1, 1), and (7, 0, -2) are linearly independent or not, we can write them as the columns of a matrix and perform row operations to see if we can reduce the matrix to row echelon form with all leading coefficients being 1.
[ -2 3 6 7 ]
[ 0 2 -1 0 ]
[ 1 5 1 -2 ]
Performing row operations, we get:
[ 1 0 0 -1 ]
[ 0 1 0 4 ]
[ 0 0 1 -3 ]
Since we have a row of zeros, the matrix cannot be reduced to row echelon form with all leading coefficients being 1. Therefore, the vectors are linearly dependent.
To know more about linearly independent,
https://brainly.com/question/31086895
#SPJ11
For the random variables below, indicate whether you would expect the distribution to be best described as geometric, binomial, Poisson, exponential, uniform, or normal. Please Explain why.The number of goals that a team scores in a hockey game.The time of day that the next major earthquake occurs in Southern California.The number of minutes before a store manager gets her next phone call.The number of 3's that appear in 20 rolls of a die.The number of days out of the next 10 that a stock will go up.The amount of time before the next customer arrives in a store.The number of particles that a radioactive substance emits in the next two seconds.The number of free throws that a basketball player needs to make before missing one.
Answers
The number of free throws that a basketball player needs to make before missing one: This can be modeled by a geometric distribution, as it involves a fixed number of independent trials with a binary outcome (making or missing a free throw) and the probability of success (making a free throw) is constant.
The number of goals that a team scores in a hockey game: Poisson distribution is often used to model the number of events occurring in a fixed interval of time when the events are rare and random.
The time of day that the next major earthquake occurs in Southern California: This can be modeled by an exponential distribution, which is often used to model the time between rare and random events.
The number of minutes before a store manager gets her next phone call: This can also be modeled by an exponential distribution, as the time between calls is often random and rare.
The number of 3's that appear in 20 rolls of a die: This can be modeled by a binomial distribution, as it involves a fixed number of independent trials with a binary outcome (rolling a 3 or not rolling a 3).
The number of days out of the next 10 that a stock will go up: This can be modeled by a binomial distribution, as it involves a fixed number of independent trials with a binary outcome (stock goes up or does not go up).
The amount of time before the next customer arrives in a store: This can be modeled by an exponential distribution, as the time between customers is often random and rare.
The number of particles that a radioactive substance emits in the next two seconds: This can be modeled by a Poisson distribution, as the number of emissions in a fixed interval of time is often rare and random.
To know more about geometric distribution,
https://brainly.com/question/10164132
#SPJ11
let x1, . . . , xn be independent and identically distriuted random variables. find e[x1|x1 . . . xn = x]
Answers
The conditional expectation of x1 given x1, ..., xn = x is E[x1 | x1, ..., xn = x].
How to find value of random variable?To find the expected value of the random variable X1 given that X1, ..., Xn = x, we need to use the concept of conditional expectation.
The conditional expectation of x1 given x1, ..., xn = x, denoted as E[x1 | x1, ..., xn = x], represents the expected value of x1 when we know the values of x1, ..., xn are all equal to x.
This expectation is calculated based on the concept of conditional probability. Since the random variables x1, ..., xn are assumed to be independent and identically distributed, the conditional expectation can be obtained by taking the regular expectation of any one of the variables, which is x. Therefore, E[x1 | x1, ..., xn = x] is equal to x.
In other words, knowing that all the variables have the same value x does not affect the expected value of x1.
Learn more about random variable
brainly.com/question/30974660
#SPJ11
Counting functions from a set to itself. Count the number of different functions with the given domain, target and additional properties. (a) f: {0,1}} →{0,1}? (b) f: {0,1}} →{0,1}? The function f is one-to-one. () f: {0,115 — {0,1}? (d) f: {0,135 → {0,1}7. The function fis one-to-one.
Answers
a) There are 2 × 2=4 different functions.
b) There are 2 × 1=2 different functions.
c) There are 222=8 different functions.
d) There are 876 × 5=1,680 different functions.
(a) For a function f: {0,1} → {0,1}, there are 2 choices for the value of f(0), and 2 choices for the value of f(1).
(b) For a one-to-one function f: {0,1} → {0,1}, we know that f(0) and f(1) must be different. There are 2 choices for the value of f(0), and only 1 choice for the value of f(1) (since it must be different from f(0)).
(c) For a function f: {0,1,2} → {0,1}, there are 2 choices for the value of f(0), 2 choices for the value of f(1), and 2 choices for the value of f(2).
(d) For a one-to-one function f: {0,1,2,3} → {0,1,2,3,4,5,6,7}, there are 8 choices for the value of f(0) (since it can be any of the 8 values in the target set), 7 choices for the value of f(1) (since it must be different from f(0)), 6 choices for the value of f(2) (since it must be different from f(0) and f(1)), and 5 choices for the value of f(3) (since it must be different from f(0), f(1), and f(2)).
for such more question on different functions
https://brainly.com/question/15602982
#SPJ11
the 90onfidence interval for p1- p2 is (-0.074, 0.028). on the basis of this interval, what should we conclude?
Answers
Based on the given 90% confidence interval for the difference between two population proportions, p1 and p2, which is (-0.074, 0.028), we can conclude that there is no statistically significant difference between the two proportions.
A confidence interval, in statistics, refers to the probability that a population parameter will fall between a set of values for a certain proportion of times.
Based on the 90% confidence interval for p1 and p2, which is (-0.074, 0.028), we can conclude that there is no statistically significant difference between the two proportions. This is because the interval contains the value of zero, which means that the difference between the two proportions is not significantly different from zero at a 90% confidence level.
However, it is important to note that this conclusion only holds true for the specific sample data used to calculate the interval and may not generalize to the entire population.
To learn more about confidence interval visit : https://brainly.com/question/15712887
#SPJ11
Can someone answer these please???
Tyler cleaned 20 ears of corn in ¾ hour, Tonya cleaned 15 ears of corn in ½ hour, Tara cleaned 30 ears of corn in 1 ½ hours, and Tony cleaned 40 ears of corn in 2 hours. Who cleaned the corn the fastest?
8. It took 12 gallons for Kyle to refill his tanks after driving 350 miles and it took 9 gallons of gas for Bertie to fill her tank after driving 312 miles. Who got the best gas mileage?
9. Kenneth mowed 3 lawns in 7 hours, Greg mowed 2 lawns in 3 hours, and Wayne mowed 5 lawns in 9 hours. Who mowed the fastest?
10. Maxine used 2 potatoes to make ½ gallon of stew. How many potatoes should she use if she is going to make a gallon of stew?
Answers
8. To find out who got the best gas mileage among Kyle and Bertie, we need to calculate their respective miles per gallon (mpg)
using the formula: mpg = miles driven / gallons of gas usedFor Kyle, mpg = 350 / 12 = 29.17For Bertie, mpg = 312 / 9 = 34.67Therefore, Bertie got the best gas mileage with 34.67 mpg.9. To find out who mowed the fastest among Kenneth, Greg, and Wayne
we need to calculate their respective lawns per hour using the formula: lawns per hour = number of lawns mowed / hours taken.For Kenneth, lawns per hour = 3 / 7 ≈ 0.43For Greg, lawns per hour = 2 / 3 ≈ 0.67For Wayne, lawns per hour = 5 / 9 ≈ 0.56Therefore, Greg mowed the fastest with approximately 0.67 lawns per hour.10. If Maxine used 2 potatoes to make 1/2 gallon of stew, then to make a gallon of stew, she would need to use twice the amount of potatoes. Therefore, Maxine should use 4 potatoes to make a gallon of stew.
Know more about calculate their respective lawns here:
https://brainly.com/question/29704262
SPJ11
The diameter of a cylindrical construction pipe is 7ft if the pipe is 34 ft long what is its volume
Answers
The volume of a cylindrical construction pipe with a diameter of 7 ft and a length of 34 ft can be calculated. The answer is provided in the following explanation.
To calculate the volume of a cylinder, we need to use the formula V = π[tex]r^2[/tex]h, where V represents the volume, r is the radius, and h is the height of the cylinder. Given that the diameter is 7 ft, we can determine the radius by dividing the diameter by 2, giving us a radius of 3.5 ft. The height of the cylinder is given as 34 ft.
Using these values, we can substitute them into the formula to calculate the volume: V = π[tex](3.5 ft)^2[/tex] * 34 ft. Simplifying the equation, we have V = π * [tex]3.5^2[/tex] * 34 [tex]ft^3[/tex]. Evaluating the expression further, V = π * 12.25 * 34 [tex]ft^3[/tex], which simplifies to V ≈ 1309.751 [tex]ft^3[/tex].
Therefore, the volume of the cylindrical construction pipe is approximately 1309.751 cubic feet.
Learn more about diameter here:
https://brainly.com/question/31445584
#SPJ11
apply the logit model to calculate the division of usage between the automobile mod (ak = -0.005( and a mass transit mode (ak = -0.05)
Answers
The predicted division of usage between the automobile mode and the mass transit mode is approximately 50% automobile and 29% mass transit, with the remaining percentage representing other modes or no mode at all.
To apply the logit model to calculate the division of usage between the automobile mode (ak = -0.005) and the mass transit mode (ak = -0.05), we need to first define the model equation:
P(auto) = exp(ak × x) / [1 + exp(ak × x)]
P(mass transit) = 1 / [1 + exp(ak × x)]
where P(auto) is the probability of using the automobile mode, P(mass transit) is the probability of using the mass transit mode, ak is the parameter associated with each mode (ak = -0.005 for automobile and ak = -0.05 for mass transit), and x is a vector of variables that influence mode choice.
To illustrate how to use the logit model, let's say we have two variables that influence mode choice: travel time (in minutes) and cost (in dollars). We can represent these variables as follows:
x = [travel time, cost]
Suppose further that we have the following values for travel time and cost:
Travel time = 30 minutes
Cost = 5 calculate the probability of using the automobile mode as follows:
P(auto) = exp(ak × x) / [1 + exp(ak × x)]
= exp(-0.005 × [30, 5]) / [1 + exp(-0.005 × [30, 5])]
= 0.5008
The probability of using the mass transit mode can be calculated as follows:
P(mass transit) = 1 / [1 + exp(ak × x)]
= 1 / [1 + exp(-0.05 × [30, 5])]
= 0.287
for such more question on percentage
https://brainly.com/question/27855621
#SPJ11
The logit model can be used to calculate the division of usage between the automobile mode and mass transit mode. The logit model assumes that the probability of choosing a particular mode of transportation depends on the cost and other characteristics of that mode.
The parameter "ak" represents the cost sensitivity of each mode. In this case, the parameter "ak" for the automobile mode is -0.005, meaning that the probability of choosing the automobile mode decreases by 0.5% for every one unit increase in cost. Similarly, the parameter "ak" for the mass transit mode is -0.05, meaning that the probability of choosing the mass transit mode decreases by 5% for every one unit increase in cost. By applying the logit model, we can determine the optimal division of usage between the automobile and mass transit modes based on the cost and other characteristics of each mode.
To apply the logit model for the division of usage between the automobile mode (ak = -0.005) and a mass transit mode (ak = -0.05), follow these steps:
1. Calculate the utility of each mode:
Utility_Automobile = exp(ak) = exp(-0.005) ≈ 0.995
Utility_MassTransit = exp(ak) = exp(-0.05) ≈ 0.951
2. Calculate the sum of utilities:
Sum_Utilities = Utility_Automobile + Utility_MassTransit ≈ 0.995 + 0.951 ≈ 1.946
3. Calculate the probability of choosing each mode:
Probability_Automobile = Utility_Automobile / Sum_Utilities ≈ 0.995 / 1.946 ≈ 0.511
Probability_MassTransit = Utility_MassTransit / Sum_Utilities ≈ 0.951 / 1.946 ≈ 0.489
The division of usage between the automobile mode and the mass transit mode is approximately 51.1% for automobiles and 48.9% for mass transit.
To learn more about cost sensitivity click here, brainly.com/question/29693841
#SPJ11
Please help me with this question as quick as you can :)
Answers
The value of h, correct to one decimal place, is 11.3 cm.
To find the value of the height (h) of the right-angled triangle with a 37-degree angle and a base of 15 cm, we can use the trigonometric function tangent (tan).
Tan is defined as the ratio of the opposite side (h) to the adjacent side (15 cm) of the 37-degree angle.
tan(37) = h/15
To solve for h, we can multiply both sides of the equation by 15:
h = 15 x tan(37)
Using a calculator, we can evaluate the tangent of 37 degrees to be approximately 0.7536.
h = 15 x 0.7536 = 11.304
For similar questions on trigonometric function
https://brainly.com/question/1143565
#SPJ11
The pressure of the reacting mixture at equilibrium CaCO3 (s) ⇌ CaO (s) + CO2 (g) is 0. 105 atm at 350˚ C. Calculate Kp for this reaction
Answers
The equilibrium constant Kp for this reaction is equal to 0.105 atm. The balanced chemical equation for the given reaction is: CaCO3(s) ⇌ CaO(s) + CO2(g)The equilibrium pressure
P = 0.105 atmThe temperature, T = 350°C To calculate the equilibrium constant Kp for the reaction, we need to use the partial pressure of the gases involved at equilibrium. In this case, we have only one gas, which is carbon dioxide (CO2).
The balanced equation for the reaction is:
CaCO3 (s) ⇌ CaO (s) + CO2 (g)
Given: Pressure at equilibrium (P) = 0.105 atm
Since there is only one gas in the reaction, the equilibrium constant Kp can be calculated as follows:
Kp = P(CO2)
Therefore, Kp = 0.105 atm.
The equilibrium constant Kp for this reaction is equal to 0.105 atm.
to know more about equilibrium constant visit :
https://brainly.com/question/28559466
#SPJ11
A person invests $800 in a bank account that promises a nominal
rate of 4. 5% continuously compounded. How much would the
investment be worth after 7 years?
Answers
The amount of interest accumulated on an investment of $800 in a bank account that promises a nominal annual interest rate of 5.5% and compounds interest semiannually after 3 years is $118.52.
The amount of interest accumulated on an investment of $800 in a bank account that promises a nominal annual interest rate of 5.5% and compounds interest semiannually after 3 years is $118.52. The formula to calculate the compound interest is: A=P(1+r/n)^(nt)Where A is the amount of money accumulated after n years, P is the principal amount, r is the rate of interest, t is the number of times the interest is compounded, and n is the number of years. Substituting the values in the formula we get: A = 800(1+0.055/2)^(2*3)A = $918.52The amount of interest accumulated is the difference between the total amount accumulated and the principal amount invested, which is $118.52.
Know more about interest here:
https://brainly.com/question/29259973
#SPJ11
show explicitly that l[x−1] does not exist.
Answers
To show explicitly that l[x−1] does not exist, we need to provide an explanation as to why this limit cannot be computed. One way to do this is to consider the behavior of the function as x approaches the point x=1 from both the left and the right.
If we approach x=1 from the left, we have x-1<0 and so l[x−1] becomes l[negative number]. However, the limit of a function as it approaches a value from the left and right must be the same in order for the limit to exist. Since l[x−1] becomes l[negative number] when approached from the left, and l[x−1] becomes l[positive number] when approached from the right, the limit does not exist.
In other words, we cannot define a unique value for l[x−1] as x approaches 1 because the function behaves differently on either side of 1. Therefore, l[x−1] does not exist.
To know more about limit visit:
https://brainly.com/question/30339394
#SPJ11
EMERGENCY HELP NEEDED!!! WILL MARK RAINLIEST!! 20 POINTS
Use the scatter plot to answer the question.
Which function rule represents the best line of fit for the data in the plot?
A. f(x)=−2x+14
B. f(x)=x+8
C. f(x)=10
D. f(x)=−1/2x+8
Answers
The function rule represents the best line of fit for the data in the plot is f(x) = -/12 x + 8
Option D is the correct answer.
We have,
From the scatter plot,
The coordinates are:
(0, 8) and (-12, 14)
Now,
The function rule can be written in the form as:
f(x) = mx + c
Now,
m ( 14 - 8) / (-12 - 0) = 6/-12 = -1/2
And,
(0, 8) = (x, f(x))
So,
8 = -1/2 x 0 + c
c = 8
Now,
Substituting m and c in f(x) = mx + c,
f(x) = -1/2 x + 8
Thus,
The function rule represents the best line of fit for the data in the plot is f(x) = -/12 x + 8
Learn more about scatter plots here:
https://brainly.com/question/30017616
#SPJ1
im answering this is class and im completely stumped.
"Nancy is having a cookout with 14 invited guests. If each guest eats 2 hot dogs, how many packs does Nancy need to purchase? If she includes 2 chocolate cakes, what is the total of Nancy's items?"
(2 packs of 8 hot dogs for $5.00)
(One whole cake is $8.99)
Answers
1. The pack of items Nancy need to purchase is 28
2. The total of Nancy's items is $52.98
How many packs does Nancy need to purchase?From the question, we have the following parameters that can be used in our computation:
Number of guests = 14
Hot dogs = 2
So, we have
Purchase = 14 * 2
Evaluate
Purchase = 28
What is the total of Nancy's items?Here, we have
2 packs of 8 hot dogs for $5.00One whole cake is $8.99She includes 2 chocolate cakes
So, we have
Total = 28 * 2/8 * 5 + 2 * 8.99
Evaluate
Total = 52.98
Hence, the total of Nancy's items is $52.98
Read more about equation at
https://brainly.com/question/148035
#SPJ1
7. Which measure of center best describes Thea data? Which measure of variability?
Answers
The measure of variability are range, variance and standard deviation
Variability refers to the spread or dispersion of data points in a dataset. It helps us understand how closely or widely the data is distributed. Measures of variability provide insights into the degree of diversity or similarity among the values in the dataset. The three commonly used measures of variability are the range, variance, and standard deviation.
Range: The range is the simplest measure of variability and is calculated by subtracting the smallest value from the largest value in the dataset. It provides a rough estimate of the spread of the data but is sensitive to outliers. Therefore, the range alone may not provide a comprehensive understanding of variability.
Variance: Variance measures the average squared deviation of each data point from the mean. It quantifies the variability by taking into account the differences between each data point and the mean. A higher variance indicates greater variability in the dataset. Variance is denoted by σ² for a population and s² for a sample.
Standard Deviation: The standard deviation is the square root of the variance. It provides a measure of variability in the original units of the dataset, making it easier to interpret. The standard deviation is denoted by σ (sigma) for a population and s (lowercase sigma) for a sample. It is widely used because it is more intuitive and easier to compare between datasets.
To know more about Variability here
https://brainly.com/question/15078630
#SPJ4